
In today’s data-driven world, search engines and databases play a vital role in handling vast amounts of information. Whether you're building a website, a search engine, or analyzing massive datasets, Elasticsearch has emerged as one of the most popular tools for indexing and searching data in real-time. But to fully utilize Elasticsearch’s power, it's important to understand how its indexing works. This post will provide an in-depth look at Elasticsearch indexing, breaking down its core concepts and explaining how it powers fast and efficient search functionality.
What is Elasticsearch?
Elasticsearch is a distributed search and analytics engine based on Apache Lucene. It is designed for scalability, speed, and flexibility, making it suitable for a wide variety of use cases such as log analysis, full-text search, data analytics, and more.
At its core, Elasticsearch allows you to store, search, and analyze large amounts of unstructured data in real-time. Indexing is the process by which data is stored and organized in Elasticsearch to make it quickly searchable. But before we get into the mechanics of indexing, let’s break down some key concepts.
Key Concepts of Elasticsearch
Before diving into indexing, understanding a few fundamental concepts is essential:
1. Document
In Elasticsearch, a document is a basic unit of data that you index. It is a JSON object that contains a set of key-value pairs. Each document is akin to a row in a traditional database table, but with much more flexibility.
Example:
{
"user": "john_doe",
"message": "Hello, Elasticsearch!",
"date": "2024-11-13"
}
2. Index
An index is a collection of documents that share the same data structure. It’s like a database in the traditional sense, but in Elasticsearch, it holds the data in a way that is optimized for fast retrieval. An index can contain one or more types of documents.
When you create an index in Elasticsearch, you define mappings, which determine how the data should be stored and indexed.
3. Mapping
A mapping defines how the fields in the documents will be indexed and stored. It’s similar to a schema in a relational database. Mappings allow you to control things like the data type (e.g., string, integer, date), how fields are analyzed, and how they are stored.
4. Shard
An index in Elasticsearch is divided into smaller units called shards. Each shard is essentially a self-contained index that can be stored on any node in the cluster. This division ensures that Elasticsearch can handle large datasets and scale horizontally across multiple machines.
5. Node
A node is a single instance of Elasticsearch running on a server. A cluster is made up of multiple nodes, which work together to store data and perform operations like indexing and searching.
What is Indexing in Elasticsearch?
Indexing in Elasticsearch refers to the process of converting your data (usually documents) into a format that can be efficiently searched and retrieved. This process involves breaking down the documents into smaller pieces (tokens), analyzing them, and then storing them in an optimized structure.
The key goals of indexing are:
- Speed: The indexed data can be searched and retrieved quickly.
- Scalability: Elasticsearch distributes the indexing process across multiple nodes and shards to scale efficiently.
- Flexibility: It supports a wide range of data types and allows dynamic mappings.
The Indexing Process
When you send a document to Elasticsearch, the indexing process involves several key steps:
-
Document Reception The first step involves receiving a document. Elasticsearch accepts documents in JSON format, with each document having an ID (which can be assigned manually or automatically).
-
Analyzing the Document Once the document is received, it is passed through an analyzer. An analyzer is a component that breaks the document down into tokens or terms that can be indexed and searched. The analyzer performs tasks like:
For example, the sentence “The quick brown fox” might be tokenized into ["quick", "brown", "fox"].
- Tokenization: Splitting the text into individual words (tokens).
- Filtering: Removing stop words (e.g., “and”, “the”) and applying other filters like stemming or lowercasing to standardize the tokens.
-
Indexing Tokens After the document is analyzed, the resulting tokens are indexed. In Elasticsearch, tokens are stored in an inverted index, which is essentially a mapping of terms to the documents in which they appear. This structure allows Elasticsearch to quickly look up documents based on the terms they contain.
-
Storing the Document After indexing, the original document is stored in Elasticsearch. The document’s fields are stored in a format that is optimized for retrieval and can be quickly accessed when performing search queries.
Inverted Index
The heart of Elasticsearch indexing lies in the inverted index. This is a data structure that helps make searches extremely fast. It essentially works like an index at the back of a book.
For example, consider three documents:
- Document 1: "Elasticsearch is powerful"
- Document 2: "Elasticsearch supports real-time search"
- Document 3: "Search engines use Elasticsearch"
An inverted index for the word "Elasticsearch" might look like this:
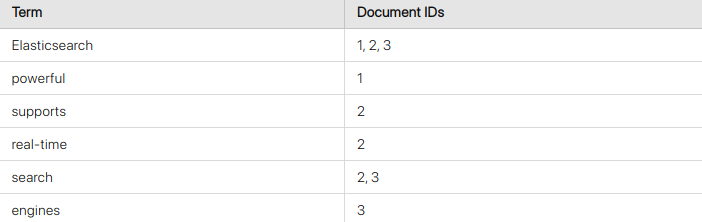
The inverted index allows Elasticsearch to quickly locate all documents that contain a specific term, improving the search speed.
Types of Indexing
Elasticsearch supports two types of indexing operations:
-
Standard Indexing In standard indexing, when you send a document to Elasticsearch, it automatically either creates a new document or updates an existing one if the same ID is used.
-
Bulk Indexing Elasticsearch also allows bulk indexing, where you can send multiple documents in a single request. This is useful when dealing with large datasets and is significantly faster than indexing documents one by one.
Indexing Strategies for Performance
When working with large datasets, there are a few strategies to optimize indexing performance:
1. Use the Right Mapping
Properly defining mappings for your data is crucial. For instance, setting a field as keyword instead of text when you don’t need full-text search can save resources and speed up indexing.
2. Optimize Shard Size
Sharding helps distribute the data, but too many small shards or very large ones can lead to performance issues. Finding the right balance for your data size and query patterns is key.
3. Batch Indexing
Instead of indexing documents one at a time, batch multiple documents together. This reduces overhead and speeds up the indexing process.
4. Disable or Reduce Refresh Interval
The refresh interval controls how often Elasticsearch makes newly indexed data searchable. For heavy indexing operations, temporarily increasing the refresh interval can improve performance.
Conclusion
Understanding Elasticsearch indexing is crucial for building fast, scalable search applications. By analyzing documents, breaking them into tokens, and storing them in an inverted index, Elasticsearch enables real-time, high-performance search capabilities. Whether you’re working with log data, e-commerce platforms, or content management systems, mastering indexing will allow you to make the most of Elasticsearch’s powerful features.
By optimizing your index mappings, shard configuration, and indexing strategy, you can ensure that Elasticsearch delivers the performance and efficiency you need for your data-driven applications.