
Elasticsearch, one of the most popular search and analytics engines, is widely used for real-time data storage and retrieval. Known for its speed and scalability, Elasticsearch powers applications ranging from search engines and recommendation systems to large-scale data analytics. However, understanding how Elasticsearch stores data can be key to maximizing its capabilities for your applications. In this blog post, we’ll explore the data storage model in Elasticsearch, breaking down how data is organized, indexed, and retrieved efficiently.
Elasticsearch’s Data Storage Architecture
Elasticsearch is a distributed, document-based data store built on Apache Lucene. It takes large datasets and stores them in a way that allows rapid search and retrieval. Unlike traditional databases, which use tables and rows, Elasticsearch stores data as JSON documents within indexes, divided into shards and distributed across nodes.
Here’s an overview of some key components of Elasticsearch’s storage model:
Key Components in Elasticsearch Storage
-
Document: The core unit of data in Elasticsearch, which contains JSON-structured information. A document is roughly equivalent to a row in a traditional database.
-
Index: A collection of documents with a similar structure, akin to a database in relational database systems.
-
Shard: A subset of an index that is stored independently. Shards allow Elasticsearch to distribute data across multiple nodes, improving scalability and fault tolerance.
-
Node: A single instance of Elasticsearch, responsible for storing and managing data within one or more shards.
-
Cluster: A collection of nodes that work together to store data, balance load, and execute queries. Clusters enable horizontal scaling and redundancy.
Each component contributes to the way Elasticsearch organizes and stores data, helping it achieve the speed, reliability, and scalability for which it’s known.
How Elasticsearch Organizes Data
1. Indexes and Types
In Elasticsearch, an index is similar to a database and is the highest-level container for documents. Each index has a unique name and is composed of one or more documents with a similar schema. Traditionally, each index could have multiple types (like different tables), but recent versions of Elasticsearch have deprecated types to simplify data modeling.
Each index has:
- Mappings: These are schemas that define the structure of data fields within documents, specifying data types (e.g.,
text,integer,date) and indexing settings. - Settings: These control various index behaviors, including the number of primary and replica shards.
Indexes help organize and logically group documents, making it easy to search and filter data by category.
2. Documents and Fields
A document is the fundamental unit of data in Elasticsearch. Each document is stored as a JSON object, consisting of fields and values. Fields are the individual pieces of data within a document, and each field has a data type, such as text, keyword, integer, date, etc.
Example of a JSON document in Elasticsearch:
{
"user": "jane_doe",
"post_date": "2024-11-13",
"message": "Learning about Elasticsearch storage!",
"tags": ["elasticsearch", "storage", "data"]
}
Elasticsearch automatically indexes fields, allowing users to search on any attribute of the document. Fields can be stored as text (for full-text search) or as keyword (for exact match and filtering). This flexible schema design enables efficient searches and analytics on large datasets.
3. Shards and Replicas
Each index is divided into shards, which are independent, smaller data containers. This sharding is crucial for Elasticsearch’s scalability and data distribution. By default, an index has five primary shards, but this can be configured based on requirements. Shards ensure that:
- Data is distributed across multiple nodes, enabling horizontal scaling.
- Large datasets are split into manageable pieces for faster data retrieval.
Each shard is also replicated to provide redundancy. Replicas ensure that if a node fails, the data is not lost, and the system remains operational. Replica shards also improve query throughput by enabling Elasticsearch to handle requests across multiple copies of the data.
The Inverted Index: Key to Fast Searches
A core feature of Elasticsearch’s data storage is the inverted index. Unlike traditional databases, which might perform slow scans to locate data, the inverted index is a data structure that enables fast lookups for search queries. It’s the backbone of Elasticsearch’s search efficiency.
How the Inverted Index Works
The inverted index maps terms to the documents they appear in, much like an index at the back of a book. For instance, if you have three documents with these contents:
- Document 1: "Elasticsearch powers search applications."
- Document 2: "Search engines benefit from fast data access."
- Document 3: "Data is stored in an inverted index."
The inverted index for the term "search" would look something like this:
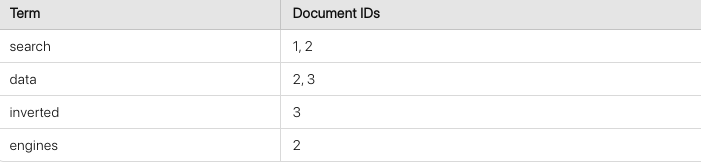
This index structure allows Elasticsearch to quickly locate documents containing specific terms, making search queries extremely efficient, even with large datasets.
Storing Metadata with the Inverted Index
Along with terms, the inverted index can store additional metadata like term frequency, positions, and offsets. This metadata allows Elasticsearch to support advanced search features, including:
- Relevance scoring: Ranking documents based on term frequency and other criteria.
- Phrase and proximity searches: Searching for phrases or terms near each other.
- Highlighting: Returning highlighted excerpts from documents.
Segment Files: Persistent Data Storage
In Elasticsearch, data is stored in segment files on disk. Each shard is divided into segments, and each segment is essentially a mini inverted index. Segments are immutable, meaning that once written, they are never changed. Instead, new data is added to new segments, while old data is marked for deletion and later removed during a process called segment merging.
Benefits of Segment-Based Storage
- Immutability: Immutable segments ensure data consistency and allow for efficient handling of updates and deletions.
- Optimized Retrieval: Because each segment is an independent index, search requests can be parallelized across segments, speeding up queries.
- Efficient Memory Use: Segments optimize memory use, allowing Elasticsearch to search large amounts of data quickly.
Merging Segments
As new documents are indexed, segments multiply, potentially leading to performance issues. To counter this, Elasticsearch uses a process called merging, where smaller segments are periodically merged into larger ones, reducing the total number of segments. Merging improves search performance and reduces memory overhead, though it can be resource-intensive, so Elasticsearch typically performs it during periods of low activity.
Document Retrieval and Real-Time Searching
Elasticsearch’s design allows it to provide near real-time (NRT) search capabilities. Once a document is indexed, it becomes searchable almost immediately, typically within a second. This NRT capability is achieved through two main features:
- Refresh Interval: By default, Elasticsearch refreshes each index every second, making newly indexed documents visible for searching.
- Caching and Filtering: Elasticsearch uses caches to store frequently accessed data, which accelerates query response times. Filters, unlike regular searches, are cached and can quickly identify matching documents, boosting performance for frequently run queries.
Optimizing Data Storage in Elasticsearch
To make the most out of Elasticsearch’s storage capabilities, here are a few optimization tips:
-
Define Mappings Carefully: Custom mappings help ensure that data is stored and indexed appropriately, improving search and storage efficiency. For instance, avoid using
texttype for fields that don’t require full-text search. -
Adjust Shard and Replica Count: Optimizing the number of primary and replica shards can improve query performance and resource use. Too many shards on a single node can degrade performance, while too few shards can limit scalability.
-
Use Bulk Indexing: If you're ingesting a lot of data at once, bulk indexing is more efficient than indexing documents individually, reducing the load on the system.
-
Tune Refresh Intervals: For high-ingestion workloads where data doesn’t need to be searchable immediately, increase the refresh interval. This reduces the frequency of index refreshes, conserving resources.
-
Monitor Segment Merges: Efficient segment merging is crucial to maintaining performance, so monitoring merge operations can help ensure that queries remain fast even as data grows.
Conclusion
Elasticsearch’s data storage model is optimized for fast, scalable data retrieval. By organizing data into indexes, shards, and segments, and using the inverted index, Elasticsearch can store and search massive amounts of information in real time. Understanding these storage mechanisms can help you make informed decisions about indexing strategies, mapping configurations, and performance optimizations, allowing you to get the best possible performance from Elasticsearch in your application. Whether you're dealing with search, analytics, or large-scale data management, Elasticsearch’s storage model is designed to handle it all efficiently.